
5G Voice Services Part-1 Updated In 2024
- K Supriya
- Aug 24, 2024
- 17 min read


Introduction To 5G Voice Services
As the telecommunications industry evolves, so does the technology that supports 5G voice services. With the advent of 5G, voice services are transitioning from legacy systems to more advanced architectures that promise greater efficiency and quality. This blog will delve into the intricacies of 5G voice services, exploring the transition from 2G/3G systems to 5G, and the new technologies that support voice over 5G.
Legacy Voice Services: 2G and 3G
Legacy 2G and 3G networks support voice services using Circuit Switched (CS) connections which benefit from dedicated resources throughout the lifetime of each call. 4G networks do not support the CS domain so arc unable to provide CS services. However, CS Fallback procedures can be used to move connections from a 4G network to a 2G or 3G network whenever there is a requirement to establish a CS connection. CS Fallback procedures rely upon the 5Gs interface between the MME and MSC when moving a connection towards GERAN or UTRAN. CS Fallback procedures can be based upon a blind release with redirection, a measurement based release with redirection or an inter-system handover.
4G Voice Services: VoLTE and OTT
4G networks can be configured to support voice services using Packet Switched (PS) connections which rely upon the Evolved Packet Core (EPC) to provide connectivity to an IP Multimedia Subsystem (IMS). The IMS provides the control plane functions which manage the setup, maintenance and release of PS voice services. These control plane functions use Session Initiation Protocol (SIP) signalling to communicate with the UE. PS voice services over LTE are known as Voice over LTE (VoLTE). PS voice services provide increased capacity and efficiency but require stringent packet prioritisation to ensure that Quality of Service (QoS) requirements are satisfied. VoLTE relies upon Single Radio Voice Call Continuity (SRVCC) to provide inter-system mobility at locations where VoLTE coverage is not contiguous. The SRVCC procedure toward either GERAN or UTRAN changes the core network domain from PS to CS.
4G networks can also support PS voice services using Over The Top (OTT) applications such as 'Skype' and 'WhatsApp'. These applications typically rely upon general data connections to support Voice over IP (VoIP) services. This means that speech packets will be handled with lower priority and the user experience may be compromised during periods of congestion. OTT applications typically use the same non-Guaranteed Bit Rate (non-GBR) EPS Bearer as used for normal data transfer. In contrast, VoLTE connections benefit from GBR EPS Bearers which are handled with high priority.
In the case of 5G, the availability of specific solutions for the voice service depends upon the Base Station architecture. The solutions associated with each architecture arc summarised in Figure below. All architectures support OTT applications because these only require a data connection which can be either an EPS Bearer towards the 4G core network, or a PDU Session towards the 5G core network.
5G Voice Services: The Transition and New Solutions
Base Station architecture 3/3a/3x is based upon a 4G Master Node connected to the 4G core network. This allows the use of all legacy 4G voice service solutions, i.e. both CS Fallback and VoLTE can be used. This is attractive when evolving towards a standalone 5G solution because it allows the data capability to be upgraded with minimal impact upon existing voice services. The call setup delay associated with the CS Fallback procedure may increase marginally when using option 3/3a/3x because the procedure will include additional X2AP signalling to release the 5G Secondary Node (assuming it has already been added at the time of the CS Fallback).

Base Station architectures 2 and 4/4a are based upon a 5G Master Node connected to the 5G core network. These require the use of new 5G voice service solutions, i.e. Voice over New Radio (VoNR), EPS Fallback and RAT Fallback. CS Fallback is not supported when using the 5G core network. EPS Fallback and RAT Fallback provide alternatives which redirect the UE towards an LTE Base Station connected to the 4G core network and 5G core network respectively.
Base Station architectures 5 and 7/7a/7x arc based upon a 4G Master Node connected to the 5G core network. These architectures support Voice over enhanced LTE (VoLTE) which relies upon the 4G air-interface to transfer speech packets belonging to a GBR QoS Flow. Base Station architecture 4/4a can also support VoLTE when the speech packets are transferred using the 4G Secondary Node. Similarly, architecture 7/7a/7x can support VoNR when the speech packets arc transferred using the 5G Secondary Node.
The release 15 version of the 3GPP specifications does not support SRVCC for 5G. Speech service continuity allocations with non contiguous 5G coverage relies upon Packet Switched inter-system handover towards 4G. SRVCC can then be completed from 4G if necessary. SRVCC from 5G to 3G (UTRAN) is planned for the release 16 version of the 3GPP specifications.
Voice Over New Radio (VoNR) In 5G Voice Services
Both VoNR and VoLTE rely upon connectivity to an IP Multimedia Subsystem (IMS) to manage the setup, maintenance and release or voice call connections. Session Initiation Protocol (SIP) is used for signalling procedures between the UE and IMS. VoNR uses a QoS Flow with 5Ql = 5 to transfer SIP signalling messages. In contrast, VolTE uses an EPS Bearer with QCI = 5. The general network architecture for SIP signalling with IMS is illustrated in Figure below.
The PDU Session provides connectivity between the UE and the User Plane Function (LJPF). The N6 interface provides connectivity between the UPF and the IMS
The 'Proxy' Call Session Control Function (P-CSCF) acts a first point of contact for the IMS, i.e. all SIP signalling is forwarded through the P-CSCF. Ifa UE is roaming then the P-CSCF will belong to the visited network. Otherwise, the P-CSCF will belong to the home network. When a UE completes the registration procedure with the IMS, the P-CSCF is responsible for routing the SIP: REGISTER message towards the 'lnterrogating- CSCF' (I-CSCF) within the home network. Once a UE has completed registration and a Serving-CSCF (S-CSCF) has been identified, the P-CSCF can forward messages directly to the S-CSCF. The p-CSCF communicates with the Policy Control Function (PCF) during the setup of a YoNR call. This communication triggers the PCF to initiate the setup of the QoS Flow with SQI 1 for the subsequent transfer of speech packets.
The 'lnterrogating-CSCF' (I-CSCF) communicates with the User Data Management (UDM) function during the IMS registration procedure. The UDM determines whether or not the UE is already registered and provides the identity of the S-CSCF if one has already been allocated. Otherwise, the I-CSCF is responsible for selecting an S-CSCF. For incoming YoNR calls, the I-CSCF is used as an entry point into the IMS belonging to the UE which is being called. For example, the S-CSCF belonging to the UE which originates the call, forwards the SIP: INVITE to the I-CSCF belonging to the UE which is responsible for answering the call. The I-CSCF can then interrogate its UDM to identify the appropriate S-CSCF to which the SIP: INVITE should be forwarded.
The 'Serving-CSCF' (S-CSCF) is responsible for processing and responding to SIP signalling messages from the UE. The S-CSCF communicates with the UDM during the IMS registration procedure. During the first stage of registration, the S-CSCF obtains an authentication vector from the UDM. During the second stage of registration, the S-CSCF informs the UDM that the UE has registered and provides its S-CSCF identity. This allows the UDM to be interrogated in the future, when there is a requirement to identify the allocated S-CSCF. During a YoNR call setup procedure, the S-CSCF interacts with a Telephony Application Server {TAS) which is responsible for providing the end-user application in combination with supplementary services, e.g. call waiting, call forwarding and call conferencing.
QoS Flows and Packet Delay Budget in VoNR Of 5G Voice Services

QoS Flows with 5QI = 5 are non-GBR but they are treated with high priority to ensure that STP signalling procedures are completed with minimal latency and high reliability. The characteristics belonging to a QoS Flow with SQI= S arc presented in Table below. This table also includes the characteristics belonging to the GBR QoS Flow with SQI= 1. This QoS Flow is used to transfer the speech packets after connection establishment.
The SMF has an opportunity to reconfigure the Priority and Averaging Window during the QoS Flow setup procedure. A lower numerical value corresponds to a higher priority so the default values provide the QoS Flow for STP signalling with a higher priority than the QoS Flow for speech packet transfer. The Averaging Window ensures that the Guaranteed Flow Bit Rate (GFBR) is maintained at a relatively consistent level as a function of time (rather than achieving the GFBR by allocating a very high throughput for a short duration. and then allocating a very low throughput for a long duration).
The Packet Delay Budget represents the maximum permitted delay between the UE and UPF. If both the originating and terminating voice call users have VoNR connections, then the total end-to-end Packet Delay Budget will include 2 x 100 ms. The ITU-T recommends a maximum packet delay of 200 ms to ensure that users arc very satisfied with their call quality (ITU-T Rec G.114).

Network Architecture for Speech Packet Transfer
The general network architecture for transferring the user plane speech packets is illustrated in Figure below. This figure illustrates paths towards another fP Multimedia network and towards a Circuit Switched (CS) network. The POU Session provides connectivity between the UE and the UPF, whereas the N6 interface provides connectivity between the UPF and the IMS:
The Breakout Gateway Control Function (BGCF) is responsible for selecting an MGCF for connections which terminate at a PSTN, and for selecting an IBCF for connections which terminate at another IP multimedia network. The BGCF has been excluded from Figure above to keep the diagram relatively simple, but the BGCF is also involved in SfP signalling procedures. It can be used to identify the next hop when routing SfP messages. If the next hop is within another IMS then the BGCF can forward the SIP messages to a peer BGCF within the other IMS.
The Interconnection Border Control Function (IBCF) is responsible for controlling the transport plane functions provided by the Transition Gateway (TrGW). The TrGW is responsible for providing the path for speech packets when the destination is another IP multimedia network. The TrGW is responsible for transcoding if the end-users are generating their speech packets with different codecs. The TrGW can also provide functions such as echo cancellation and the detection of inactivity.
The Media Gateway Control Function (MGCF) provides control plane inter-working towards circuit switched networks. It is responsible for the translation between the SIP messages used by the IMS and the corresponding messages used by the CS domain network, e.g. BICC messages. Within the context of the user plane, the MGCF is responsible for managing the IP Multimedia Media Gateway (IM MGW), The IM MGW and TrGW have similar responsibilities but the IM MGW provides connectivity towards a CS domain network rather than an IP Multimedia network.

Radio Access Network Protocol Stacks
Figure below illustrates the Radio Access Network protocol stacks for both SIP signalling and the end user speech packets. SIP signalling messages can be transferred using either TCP for reliability or UDP for lower latency. The upper IP layer is used for routing the packets to the P-CSCF. The SDAP layer provides the mapping between the QoS Flow associated with the higher layer packets and Data Radio Bearer (DRB) used to transfer the packets across the Radio Access Network. The PDCP layer provides ciphering and integrity protection. It also adds a sequence number for re-ordering and duplicate packet detection. The RLC layer operates using Acknowledged Mode (AM) to allow ARQ re-transmissions. The MAC layer provides support for HARQ re-transmissions to help avoid the requirement for the slower RLC re-transmissions. Layer 1 supports the New Radio (NR) air-interface
The Base Station adds header information belonging to the PDU Session User Plane protocol before forwarding uplink packets across the NG-U interface. This header information identifies the QoS Flow to which the packet belongs. A GTP-U tunnel is then used to transfer the higher layer IP packets towards the UPF. The GTP-U tunnel operates over UDP and IP layers. This means that packets transferred across the NG-U interface have two IP headers an upper layer IP header which addresses the P-CSCF, and a lower layer IP header which address the UPF (assuming uplink packet transfer).

Enhanced Voice Services (EVS) Codec
The 'Enhanced Voice Services' (EVS) codec is the current recommendation for 5G. This codec was introduced within the release 12 version of the 3GPP specifications and is already used by 4G networks
The EVS codec supports arrange of sampling frequencies to capture a range of audio bandwidths. These sampling frequencies are categorised as Narrowband, Wideband, Super Wideband and Fullband. Table below presents the set of codec bit rates which can be generated by each sampling frequency.
The codec is responsible for generating speech packets by sampling the audio and subsequently encoding to generate packets of a specific size. The encoded packet size determines the bit rate of the codec. Speech packets are generated once every 20 ms during periods of speech activity so the bit rate is given by: packet size/ 0.02. The bit rate can vary as a function of time as the codec adapts to the channel conditions, i.e. the codec can generate low bit rates for poor channel conditions and high bit rates for good channel conditions.
Sampling Frequencies and Bit Rates
The EVS codec supports a range of sampling frequencies, which correspond to different audio bandwidths:
Narrowband (8 kHz): Captures audio up to 4 kHz.
Wideband (16 kHz): Captures audio up to 8 kHz.
Super Wideband (32 kHz): Captures audio up to 16 kHz.
Fullband (48 kHz): Captures audio up to 24 kHz.
The Nyquist theorem dictates that to accurately capture audio, the sampling frequency must be at least twice the maximum audio frequency. For example, CD-quality audio uses a 44.1 kHz sampling frequency to capture audio bandwidth up to 22.05 kHz. The EVS codec's Wideband sampling frequency of 16 kHz generates a raw bit rate of 256 kbps (16 bits per sample x 16,000 samples per second), which is then compressed to a bit rate between 5.9 kbps and 128 kbps depending on network conditions.
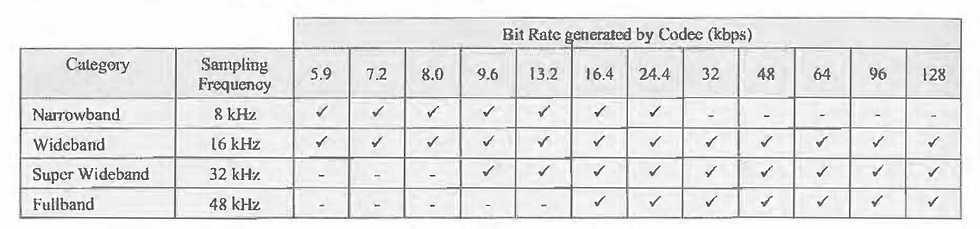
Each sample of the audio wave form generates a 16 bit Pulse Code Modulation (PCM) word. As an example, the 16kHz Wide band sampling frequency generates a bit rate of 16 x 16 000 = 256 kbps. The encoding process reduces this throughput to a level between 5.9 and 128 kbps. The codec can change the bit rate every 20 ms to adapt to the current channel conditions.
The EVS codec is capable of transferring either mono-stereo content. Stereo content is generated by encoding two mono channels. This means that the throughputs presented 111 Table above are doubled when transferring stereo content.
The EVS codec can be used in an AMR-WB 'Inter-Operable' (10) mode. This mode provides compatibility with the legacy AMR-WB codec, which means that speech packets generated by the EVS codec can be decoded by the AMR-WB codec, and vice versa. This avoids the requirement for transcoding when using a combination of EVS and AMR-WB codecs.
Stereo and Inter-Operable Modes
The EVS codec can add header information to the speech packets before passing them to the Real-time Transport Protocol (RTP) layer. This means that the throughputs generated by the codec can be higher than the figures presented in Table above. The inclusion of header information can change between individual speech packets.
Header Information in EVS Packets
The requirement for header information depends upon the use ofspecific codec functionality. For example, requesting changes to the received speech codec bit rate requires header information. Similarly, the transmission of stereo content also requires header information. 3GPP TS 26.445 specifies two categories of header information:
Compact Format: EVS Primary mode: speech packets are transferred without header information. The receiver deduces the codec bit rate from the size of the received packet. This category can be used for the transmission of single mono speech packets when there is not a requirement to include Codec Mode Request (CMR) information.
EVS AMR-WB IO mode: speech packets are transferred with the addition of a 3 bit Codec Mode Request (CMR) field. The CMR field can be used to request a specific codec bit rate from the peer codec at the remote device. The set of3 bits are used to specify one of seven AMR-WB bit rates ranging from 6.6 kbps to 23.85 kbps.
Header-Full Format: allows the inclusion of 'Table ofContent' (ToC) and 'Codec Mode Request' (CMR) headers (illustrated in Figure below). Each ofthese headers occupies 1 byte. The codec may also include zero-padding bytes to ensure that the resultant packet size does not equal one ofthe 'protected' sizes used by the Compact Format. If a codec receives a speech packet size equal to one of the 'protected' sizes then the codec deduces that it has received a Compact Format speech packet and the bit rate is then deduced from the size of the packet. Thus, it is necessary to avoid generating packets with a 'protected' size when using the Header-Full Fonnat otherwise the receiving codec would assume that it is a Compact Format packet.

Silence Insertion Descriptor (SID) Packets
The ToC header byte is used to identify the type of speech packet included within the payload. It includes a Header Type identification bit (H) which is always set to'()'. The 'F' field indicates whether or not another ToC header byte follows the current header byte. Multiple ToC header bytes are included when transferring multiple speech packets, e.g. when transferring stereo content. The first bit of the Frame Type (FT) field indicates the codec operating mode (EVS Primary Mode or EVS AMR-WB 10 mode). The last four bits of the FT field indicate the codec bit rate, i.e. the speech packet payload size. These last four bits can also indicate the transfer of a Silence Insertion Descriptor (SID) packet.
The EVS codec generates SID packets during periods of speech inactivity. These packets are used to generate 'comfort noise' at the receiving codec to avoid the remote user hearing complete silence and thinking that the connection may have dropped. SID packets generated by the EVS codec have a size of 48 bits which corresponds to a codec bit rate of 2.4 kbps. SID packets are typically transferred once every 160 ms rather than once every 20 ms. However, SID packets can be transferred more frequently and can be configured to use an adaptive mode which changes the transmission rate according to the Signal to Noise Ratio (SNR) (within this context SNR refers to audio Signal to Noise Ratio rather than RF power Signal to Noise Ratio).
Codec Mode Request (CMR) Header
The CMR header byte illustrated in Figure below is used to request a .specific operating mode and bit rate from the peer codec at the remote device. It includes a Header Type identification bit (H) which is always set to '1'. The Type of Request (T) field is used to specify the requested operating mode in terms of Narrowband, Wideband, Super Wideband, Fullband and AMR-WB 10. The Requested Bit Rate (D) field is used to specify the requested bit rate belonging lo the requested operating mode.
Real-Time Transport Protocol (RTP) and UDP
The Real-time Transport Protocol (RTP) is specified by the IETF within RFC 3550. It has been designed to transfer real time audio and video content across IP networks. The RTP layer provides services which include payload type identification, sequence numbering and time stamping. The RTP layer does not provide support for retransmissions.
The RTP header has a minimum size of 12 bytes. These 12 bytes are illustrated in Figure below.

RTP Header Structure
The RTP header fields include:
Version: signals the version of the RTP protocol (2 bits)
Padding (P): indicates whether or not there is any additional padding at the end of the RTP packet ( 1 bit)
Extension (X): indicates whether or not an extension header is present between the fixed header and the payload (only fixed header is shown in figure above) ( 1 bit)
CSRC Count (CC): defines the number of Contributing Source (CSRC) identifiers which follow the fixed header. These are applicable when the data stream originates from multiple sources (4 bits).
Marker (M): defines a flag which can be used by the application layer. It is intended to allow events such as frame boundaries to be marked in the packet stream (1 bit).
Payload Type (PT): signals the content of the payload so the n!cciving application layer can interpret it appropriately. The payload type defines the codec and indicates if the content is audio or video (7 bits)
Sequence Number: is incremented by I for every RTP packet which is sent. The sequence number is used for re-ordering and packet loss detection at the receiver (16 bits)
Time Stamp: is used by the receiver to playback the received data frames at appropriate time intervals (32 bits). The EVS codec uses a timestamp clock frequency of 16 kHz so each unit corresponds to 1/ 16000 = 0.0625 ms. This means that consecutive speech packets should have time stamps which increase by 20 / 0.0625 = 320
Synchronisation Source (SSRC) Identifier: is used lo identify !the source ofa data stream (32 bits)
Real-Time Transport Control Protocol (RTCP)
The Real-time Transport Control Protocol (RTCP) is specified by the IETF within RFC 3550. It operates in combination with the RTP layer. The RTCP layer with the receiving device collects statistics regarding the quality of the received speech signal. These statistics are sent back to the transmitting device where they can be used to adapt the transmitted signal, e.g. step down to a lower codec rate when the received signal quality is poor.
User Datagram Protocol (UDP)
The User Datagram Protocol (UDP) layer is specified by the IETF within RFC 768. It provides a simple solution for transferring data without providing services for retransmissions nor sequence numbering. UDP is often used rather than TCP for time sensitive applications because packet loss can be preferable to packet delay. The UDP layer differentiates between RTP and RTCP payloads using the Port Numbers within its header information. Packets belonging to the RTP layer are allocated an even Port Number, whereas packets belonging to the RTCP layer arc allocated the next higher odd Port Number. The same Port Numbers should be used for both sending and receiving packets.
Figure below illustrates a UDP header. It has a fixed size of 8 bytes

UDP Header Structure
The UDP header fields include:
Source Port: identifies the port number used for transmission at the sending device ( 16 bits)
Destination Port: identifies the port number used for reception at the receiving device ( 16 bits)
Length: indicates the total number of bytes within both the UDP header and the payload (16 bits)
Checksum: can be used by the receiver for error checking across both the UDP header and the payload (16 bits)
Internet Protocol (IP) Layer
Internet Protocol version 4 (IPv4) is specified by the IETF within RFC791, whereas Internet Protocol version 6 (IPv6) is specified by the IETF within RFC 2460. This section focuses upon IPv6. The iP layer provides support for packet delivery from a source IP address to a destination IP address. The RTP/UDP and RTCP/UDP packets are sent in separate iP packets.
An 1Pv6 header has a minimum size of 40 bytes (an IPv4 header has a minimum size of 20 bytes). The minimum 40 bytes of an IPv6 header are illustrated in Figure below.

IPv6 Header Structure
The IPv6 header fields include:
Version: identifies the version of the 1P protocol, i.e. version 6 (4 bits)
Traffic Class: specifics the priority using a Differentiated Services Code Point (DSCP) value. The DSCP determines the Per Hop Behaviour (PHB) to be applied by each node within the IP network, i.e. the DSCP determines the prioritisation of the packet. The DSCP value occupies 6 bits. The remaining 2 bits can be used for Explicit Congestion Notification (ECN) to indicate network congestion (8 bits)
Flow Label: can be used to identify a specific flow of packets between the source and destination 1P addresses. This allows routers to apply different packet handling rules to different packet flows (20 bits)
Payload Length: specifies the length of the payload which follows the 40 bytes of header information. The Payload Length is specified in units of bytes. Extension headers are included within the Payload Length ( 16 bits)
Next Header: specifics the content of the payload. When transferring speech packets using RTP and UDP. the Next Header field indicates that the payload includes a UDP packet (8 bits)
Hop Limit: is used to limit the number of hops when delivering a packet to the destination IP address. Each node which forwards the packet reduces the Hop Limit by '1'. The packet is discarded if the Hop Limit reaches 0 (8 bits).
Service Data Adaptation Protocol (SDAP)
The Service Data Adaptation Protocol (SDAP) is specified by 3GPP within TS 37.324. The SDAP layer is responsible for mapping packets belonging to a specific QoS flow onto an appropriate Data Radio Bearer (DRB), and vice versa at the receiver. The SDAP layer can be configured by the RRC layer to operate either with or without header information. When header information is included, it generates an overhead of 1 byte. Header information is required when using reflective QoS or when it is necessary to explicitly specify the QoS Flow to which a packet belongs. This section assumes that an SOAP header is not necessary for VoNR.
Packet Data Convergence Protocol (PDCP)
The Packet Data Convergence Protocol (PDCP) is specified by 3GPP within TS 38.323. The PDCP layer provides header compression for both the RTP and RTCP packets. Header compression is a requirement for VoNR due to the significant overhead added by the RTP, UDP and IP protocol stack layers. Speech packets have overheads added by all three of these layers whereas RTCP packets have overheads added by the UDP and IP layers. Header compression is based upon the Robust Header Compression (RoHC) framework specified within TETF RFC 3095 and RFC 4815.
Conclusion
5G voice services represent a significant evolution in mobile communication, building on the advancements of 4G while introducing new technologies and architectures. With solutions like VoNR and the EVS codec, 5G aims to deliver superior voice quality, reliability, and efficiency. As 5G networks continue to expand, these advancements will play a crucial role in shaping the future of mobile voice communication.
Comentarios